I’m testing the lightdb_stream sample program using SparkFun Thing Plus nRF9160 and was running fine for a few hours. But then I got “golioth_system: Receive timeout” warning message and it stopped sending data.
I changed the uplink frequency from 5sec to 30min and repeated the test. This time, it sent the new data after 30min, but then 20 min later I got the same warning message and it won’t recover until I reset the board.
Has anyone experience similar issues? If yes, please help!
Also, is there an example on how to implement a watchdog?
No, I did not call out a specific version. I just used the standard sample program which I first downloaded on 10/31, but I’ve done west update before compiling it today.
Btw, I reset the board and it’s currently been running for 3hrs. I’ll let you know when it stops again.
Hi @mike, here’s the hash of the Golioth SDK: e77f9355307d1177c3b569cbda3ea796f59955a7
After the last reset, so far it’s been running for almost 12hrs with no issue (only sending new values every 30min). I plan to run it for several days.
Thanks for reporting and sending over the hash. I’ve checkout out the same version of Golioth and have my Sparkfun Thing Plus nrf9160 running the lightdb_stream sample to see if I can replicate the same behavior you are seeing.
As a workaround while we troubleshoot this, the watchdog timer you mentioned isn’t a bad idea. Zephyr has a watchdog sample that you can use as an implementation guide. I checked and this board already has a watchdog0 node in the Devicetree.
Thank you @mike, I’ll try the watchdog timer. Btw, the board didn’t reset automatically after flashing so I wonder if the reset pin was set correctly. Where is this being defined?
FYI, the issue is intermittent. Over the weekend it was running for more than 29 hrs before I reset it accidentally. But today it stopped again after ~16 hrs.
So far I’m 22 hours in and haven’t encountered the issue yet.
[22:15:11.331,420] <dbg> golioth_lightdb_stream: main: Sending temperature 24.000000
[22:15:11.977,966] <dbg> golioth_lightdb_stream: temperature_push_sync: Temperature successfully pushed
[22:15:16.978,027] <dbg> golioth_lightdb_stream: main: Sending temperature 24.500000
[22:15:18.063,171] <dbg> golioth_lightdb_stream: temperature_push_handler: Temperature successfully pushed
[22:15:21.978,759] <dbg> golioth_lightdb_stream: main: Sending temperature 25.000000
Do you get any other messages after the Receive Timeout? I would expect the stream to keep trying to send data and spitting out failure messages.
Regarding the reset pin: I also have the issue that the board needs manual reset after flashing. I don’t know if this is a problem with the board mapping or not. The workaround I’ve used is to flash it using:
west flash -r jlink --reset-after-load
I’ve tried putting the reset-after-load flag into the board_runner_args in board.cmake but haven’t have success with that yet.
Hi @mike, I’m glad that you’re able to replicate the issue. On my setup, I get one last attempt of sending data (see below) after the Receive Timeout before it got hang. No failure messages after that. Is it the same in your setup?
Likely the loop was still running when the timeout occurred and you get one more send attempt before the synchronous call halts main thread flow.
To us the Receive Timeout appears to be the correct failure mode, but the system client should try to reconnect automatically, which isn’t happening. Thanks for reporting this, it will be nice to get it fixed!
Hi @invosa, sorry for the long delay without an update.
We have continued to troubleshoot this problem and have narrowed it down to the disconnect action not returning when the timeout happens. We’re continuing to drill down to pinpoint the problem (I have another test running now) with the time between replicating the failure being the blocker.
We’ll keep on it and post back here with updates. Apologies that I don’t have more concrete info for you right now.
Our Firmware team just merged a fix for the Receive Timeout issue you reported. You can pull your Golioth SDK to the tip of main to incorporate the fix. If you’re curious, here is the actual commit.
Thank you again for reporting this issue. It was a bit difficult to replicate the failure and the info you sent over about it made it much easier for us to troubleshoot.
Hi @mike, thank you for the follow-up! I’ll pull the latest SDK with the fix and do the long-run test again. Will let you know if I see any other issues.
Hi @mike, I’m just curious. After I did west update, I checked the SDK hash but found it didn’t change and confirmed that the sockets_offload_poll_wrapper.c remains unchanged. I had to do git stash followed by manual git pull to get the latest fix. Isn’t west update supposed to do that for me?
Hi @invosa, this is one of those “it depends” answers
If you installed your Zephr workspace following our quickstart guide, then the Golioth SDK is outside of the scope of west.
The west update command uses a west.yml manifest file to make changes. In this case, that file is called west-ncs.yml part of the Golioth Zephyr SDK. So the manual git pull updates the SDK and if there were changes to the manifest file (what version of NCS we’ve validated) then the west update will make sure to reset your workspace to match.
In contrast, if you used what we have been calling a “standalone repo”, we include Golioth via the manifest file. Looking at the contents of one such file, you can see that we specify the revision for Golioth, then import the west-zephyr.yml from the Golioth SDK. In this case, west update will pull the entire workspace, including Golioth.
The topic is further complicated because the Golioth Zephyr SDK can be used for both “vanilla” Zephyr and Nordic’s NCS flavor of Zephyr. This is why the Golioth SDK contains more than one west manifest.
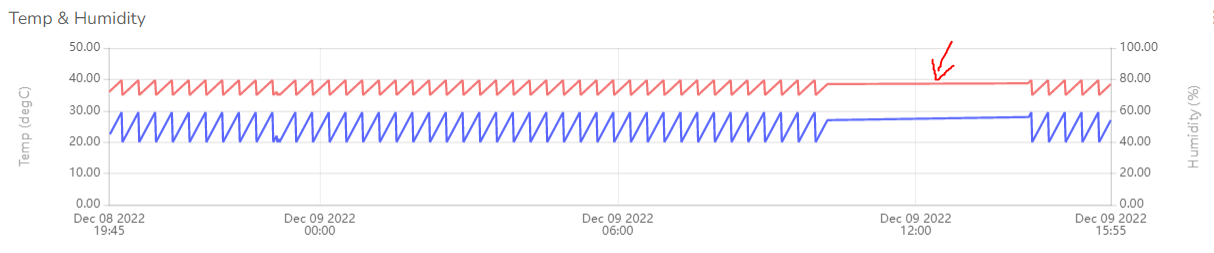
Btw, I’ve got an update for the test with the fix. The “Receive timeout” still occurs (5 times over the course of 16 hours). But the good news is, it doesn’t get stuck anymore. However, just noticed that there’s a period where it stopped sending data as you can see from the log below, although it was able to recover about 4 hours later. I have also attached a graph that shows when this happened.